
《台大机器学习基石》Multiclass-Classification
Multiclass-Classification
Perceptron Learning Algorithm,Logistic Regression这些算法的最初出现都是基于2分类的(Binary Classification),但是生活中会出很多多分类的问题出现(比如选择题:四选一,视觉的识别,手写体的识别之类的)
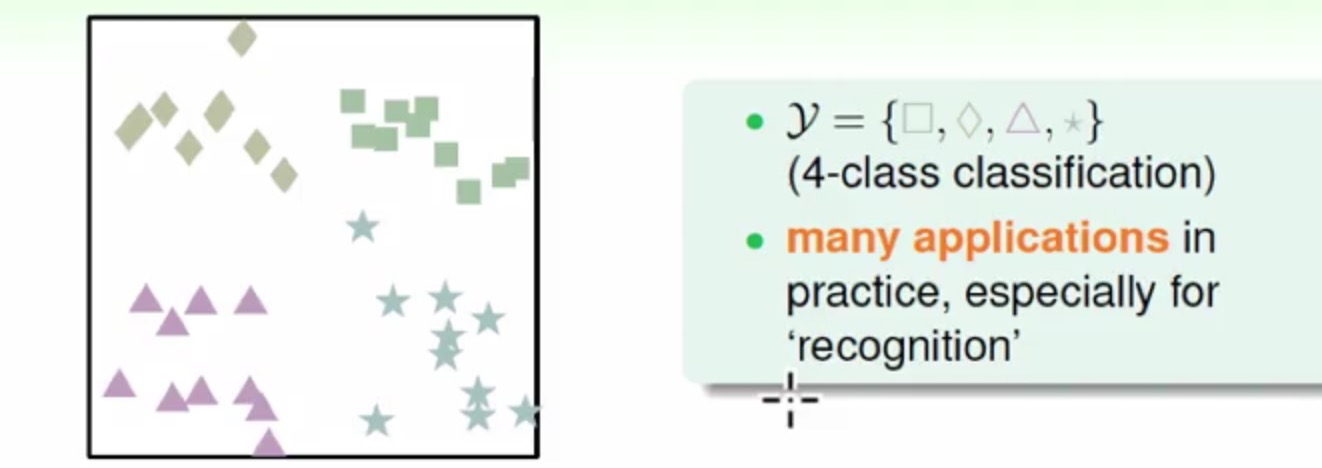

One-Vs-All
这里可以先采用一对多的方法来进行多分类,以上面的4个不同形状的多边形分类为例:
这是将方块作为一类,其余作为另一类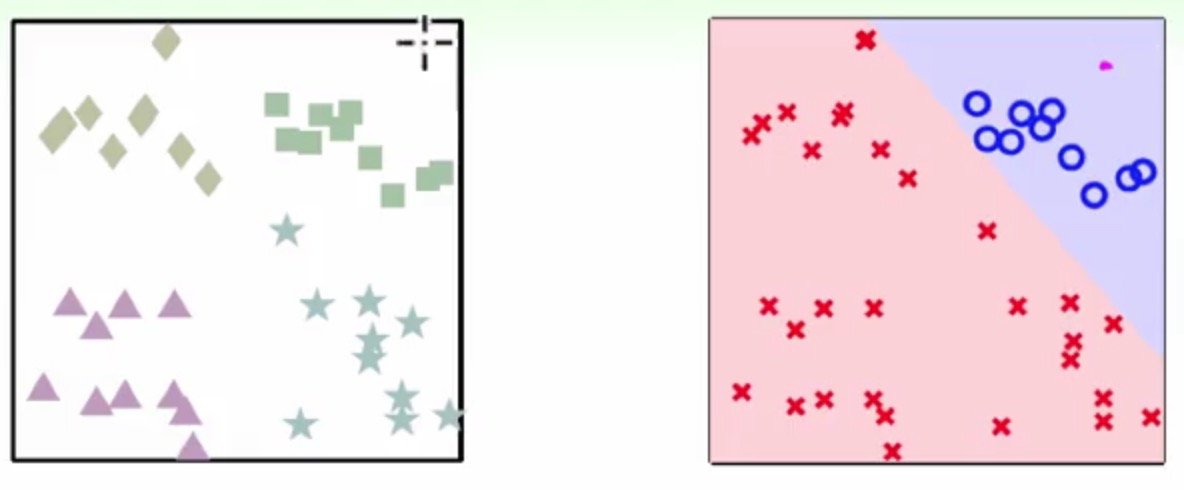
也其实就是一个二分类问题了,通过这个分类器我们可以至少将方块给区分出来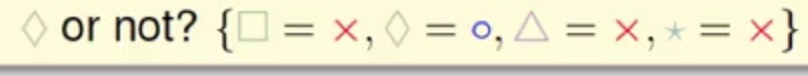
这是一个菱形作为一类的方案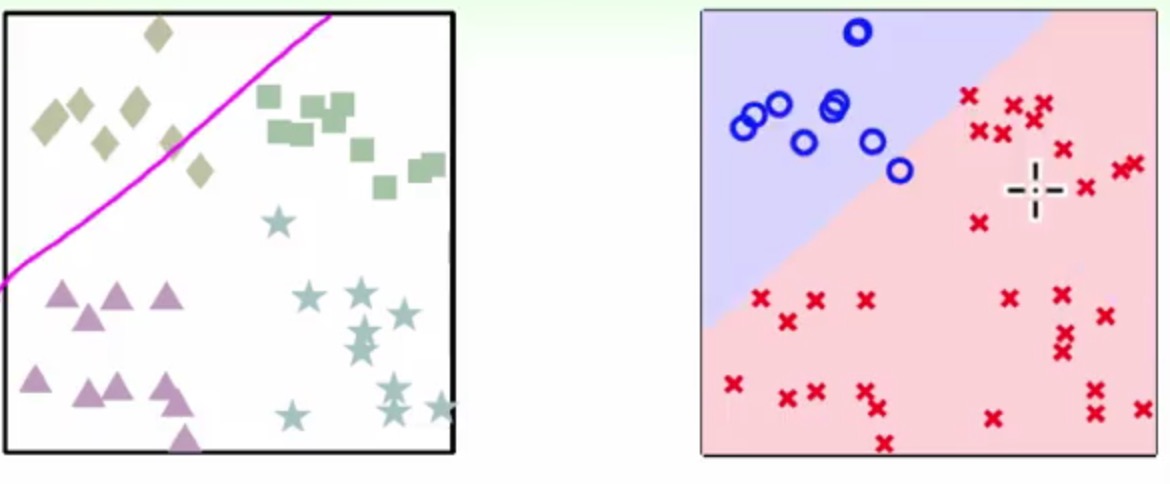
同理就会有4个区分不同形状的分类器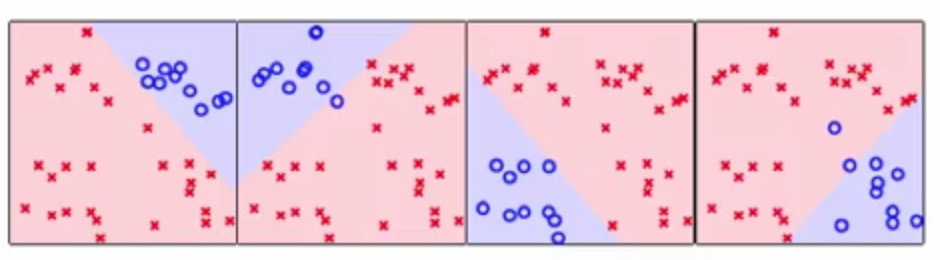
那么原图上四个角可以进行很容易得分类的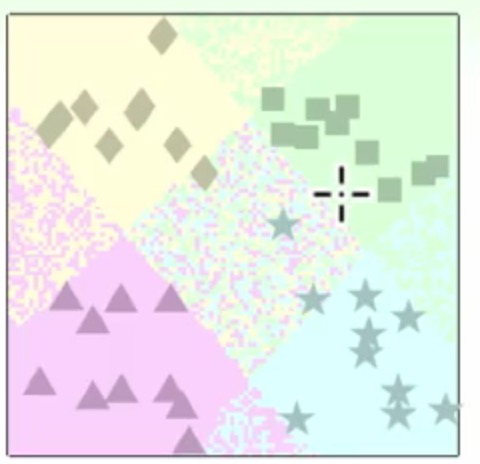
那么问题来了: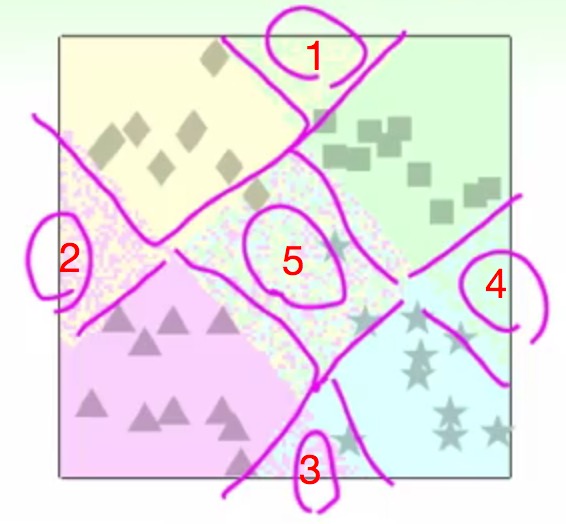
- 在1,2,3,4四个区域是每个单分类器的交集处,就会出现不知道这个分类应该属于哪个类额
- 还有在5这个区域,没有一个分类器去涉及它,就会成为了4不管区域了-_-
这里可以用一个软性(softly)的方法来解决这个问题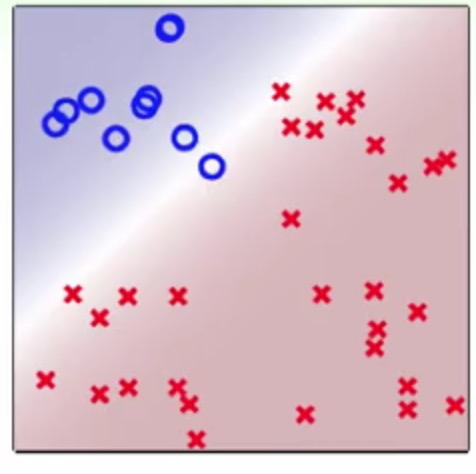
颜色越深的区域属于这个类的概率越大,也就是
那么之后形成的4个形状各自的分类器为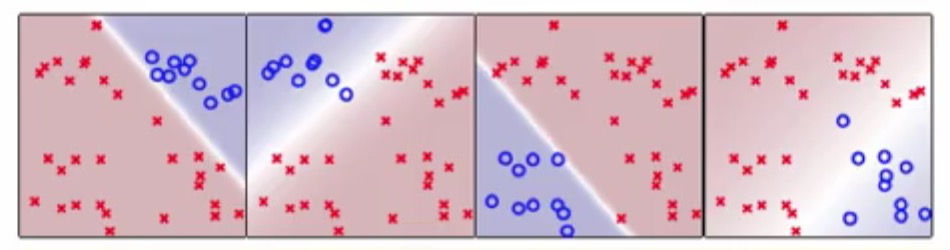
使用这种软性分类器最终的多分类判别方式是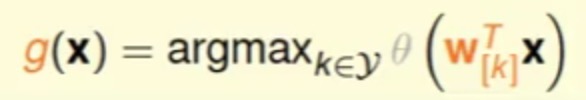
也就是它会取分类概率那大的那个类别作为预测出来的分类
这种软性多分类的分类能力为
可以发现图中的4中形状的类别都基本已经分开了
现在以Logistic Regression为例来总结一下One-Vs-All的多分类过程
- 首先是遍历每个类别,被遍历的类别作为
positive,其余的类作为negitive类别,使用Logistic Regression来训练一个分类器 - 这样遍历完了之后就可以得到
k(表示类别的种类数)分类器(这样也可以将每个分类器对应到一个类别) - 在预测阶段输入一个样本,计算出概率最高的分类器作为预测的类别
这种分类方法:
- 优点:效率很高,有多少个类别就训练多少个分类器就可以完成多分类,并且普适性还比较广,可以应用于能输出值或者概率的分类器
- 缺点:就是有较大的样本不平衡,比如现在有很多个类别,每个类别都是只占其中一点点的样本,那么每个单模型在训练的时候可能都是偏向于
negitive,最终在预测的时候就是相当于在一端偏向negitive的模型中找positive的分类器
One-Vs-One
相当于One-Vs-All的方法,这里的One-Vs-One是从多个类别里面随便选两个出来进行分类,
比如还是以上面的四种形状分类为例,先单独拿出菱形和方块这两种类别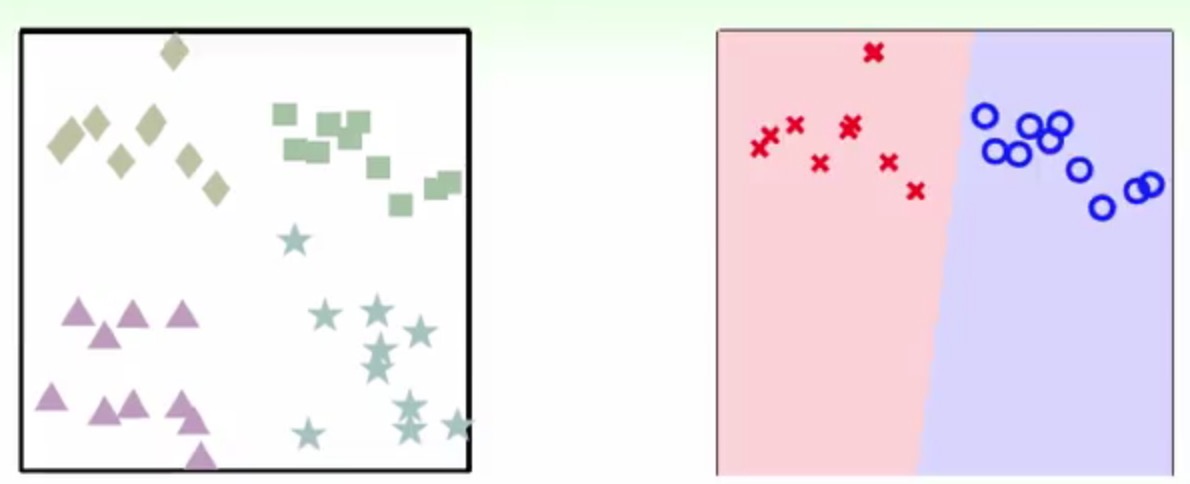
然后单独对这两个类别做一个二分类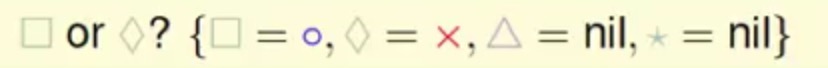
还可以做
方块和三角形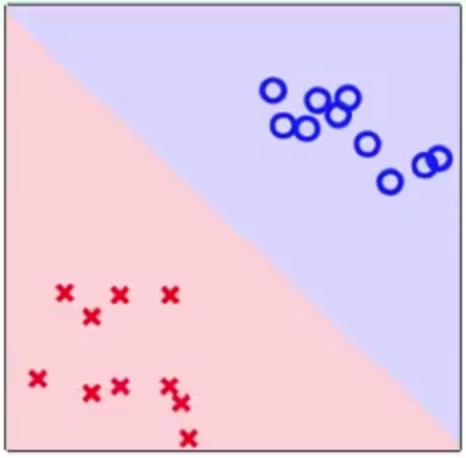
方块和星星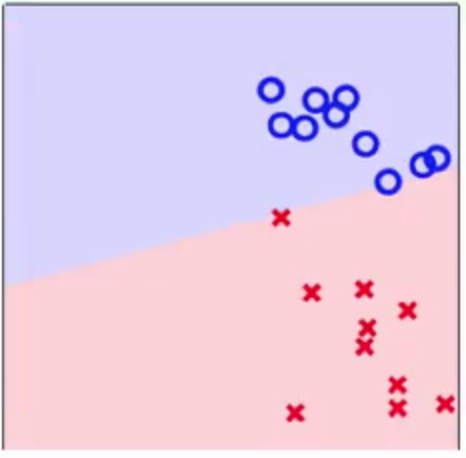
等等还有其他的。。它在四种类别中就会有6种不同的方法(N(4,2),用于表示4的2组合)
现在将这个问题想做是4支队伍,两两对战,然后取出一组成绩最好的作为预测类别,也就是一种投票分类
所以关于上述分类的公式是
再来撸一下One-Vs-One的流程:
- 遍历
k个类别,两两之间进行组合,那么就会有C(k,2)组 - 对那么多组进行一个单独进行分类训练
- 训练完了之后最终模型的预测输出使用投票的方法

这种分类方法有
- 优点:高效,别看它分为了
N(k,2)个模型,但是每个训练的时候他的训练样本只有针对训练类做一下,并且还比较稳定 - 缺点:预测的时间会变久,需要更加多得训练
总结
假设现在有k个类别,现在需要使用多分类的方法去预测一个样本属于具体哪个类
One-Vs-All:其中一个类别作为一类,剩余其他类作为一类训练一个二分类模型,按次方法共训练k模型,一般可以认为一个模型对应一个类别,预测时候取概率最大的那个模型即可
优点:训练速度快
缺点:会导致样本不平衡One-Vs-One:两两类别之间取数据进行二分类模型的训练,按此方法共训练N(k,2)个模型,在预测的时候使用投票的方法作为最终结果
优点:高效(因为每个单模型并不是训练全部数据),稳定
缺点:预测时间会变很久
参考
- 《台湾国立大学-机器学习基石》第十一讲
配图均来自《台湾国立大学-机器学习基石》
本作品采用[知识共享署名-非商业性使用-相同方式共享 2.5]中国大陆许可协议进行许可,我的博客欢迎复制共享,但在同时,希望保留我的署名权kubiCode,并且,不得用于商业用途。如您有任何疑问或者授权方面的协商,请给我留言。
